How to use Jupyter Book
Contents
How to use Jupyter Book¶
This document/website that you’re reading right now is created using Jupyter Book. Here, we will take a moment to explain the UI to help you get the most out of the experience.
Tip
As with any other tool, there will be a learning curve; however, over time, we believe this method is a lot faster and cleaner than other methods (e.g., Excel). It’ll be more creative and fun too. 🙂
Contents¶
Navigating the curriculum¶
For the most part, you can use the navigation panel on the left to jump quickly to the exercise you’re interested in.
The Lab X pages will have a more detailed summary of all of the associated exercises for that lab, which can be expanded by clicking the down chevron (⌄).
Feel free to click around and then come back to this page.

Interactivity¶
Several of the pages of this book are actually Jupyter notebooks, which provide interactive programming environments that interleave text, code, and graphics to provide hands-on learning experiences for students. On these pages, you will be able to run Python code in real time, both for the tutorials to learn the commands and for your actual laboratory data analysis. The interactivity is enabled through the campus JupyterHub, which runs Jupyter notebooks in the cloud so you don’t have to manage your own software. It’s a blessing!
Why Python? 🐍¶
There are many programming languages one can choose from, and we eventually settled on Python as it has skyrocketed in popularity in recent years. This growth is in part due to:
Its readability. Python is designed to be simple and reads like English.
Its extensibility. Python makes it easy for developers to write modules that extend its functionalities for applications in data science, scientific computing, and flying drones on Mars.
Its open-source properties. This means anyone can contribute to Python development and anyone can use it—for free!
Note
There are many similarities between Python and MATLAB, but the latter doesn’t interface well with Jupyter Book/Hub (yet). You could conceivably follow these instructions and write analogous code in MATLAB, but we invite you to give Python a try in the JupyterHub, and we believe that open-source codes (e.g., Python, Julia) will become even more prominent in your future work.
Launching JupyterHub¶
To launch any notebook in the JupyterHub, hover over the icon in the top-right corner, then Ctrl+click the button 🪐JupyterHub (open in new tab), and wait for the Hub to spawn an environment. You may have to periodically login using your CalNet credentials and approve Canvas authorizations. Note that not all pages are interactive, and thus not all pages will have the rocket symbol; we will also try to indicate interactive pages with a 🚀 emoji in the navigation bar.
Attention
Try it now by clicking on the for this page and read the rest of the page in JupyterHub!
Running a Jupyter notebook¶
The information in Jupyter notebooks is organized into cells, which come in many forms.
This cell is called a Markdown cell, which is used for text/media that can be formatted with the Markdown markup language.
You know this is a Markdown cell because when you select this cell (click on it such that a blue bar appears on the left), the menu bar at the top shows “Markdown v” in the second row:

Code cells¶
Notice how the next cell looks a little different. It is a code cell, which you can distinguish in a few ways.
If you click in the cell, the menu bar at the top will now show “
Code v.”The cell will always have a gray background.
You may also notice a
In [ ]:tag in the left margin.
You can write Python code in these cells and then execute the code with Shift+Enter. Or you can click the ▶ Run button in the menu bar to execute the code.
Quick exercise: In the space below, enter your name between the quotation marks and then run the code cell by pressing Shift+Enter.
# inline comments in Python start with "#"
name = "" # enter your name here as a string, enclosed by quotes
print(f'Hello, {name}!')
You should see some output and a number appear between the square brackets!
(e.g., In [1]:)
This number indicates the sequence of code cell execution, which can be handy for a few reasons:
You can clearly tell which cells have been executed and which cells have not.
You can split code among several code blocks and run them in whatever order you want.
You can easily change an earlier code cell and rerun it.
Benefits of JupyterHub¶
If you are a UC Berkeley student, you may be reading this Jupyter notebook on the school’s DataHub (a JupyterHub instance), thanks to the support of CDSS. With DataHub, all of our Python code will be executed and saved in the cloud, even when you close a notebook. We’ll now quickly demonstrate how to navigate to the root directory for you to see all the files in DataHub and upload new ones (e.g., your data) as needed.
Uploading your own data¶
While we’ve structured the coding and data analysis, you will still have to supply the raw data that you’ve collected. Moreover, if there are any files produced by the code (e.g., figures), you will have to download those onto your computer before inserting them into your lab writeup. Luckily, it’s quite easy to interface with DataHub to upload/download files so you can use them in your notebooks.
First navigate to the root DataHub directory with all of your sessions: https://datahub.berkeley.edu is the URL, or you can click the 🪐jupyter logo in the top-left corner. Then enter the folder of the lab that you’re working on, by clicking 📁 > mse104l > lab#. An example of the Lab 1 folder is shown in the following image:
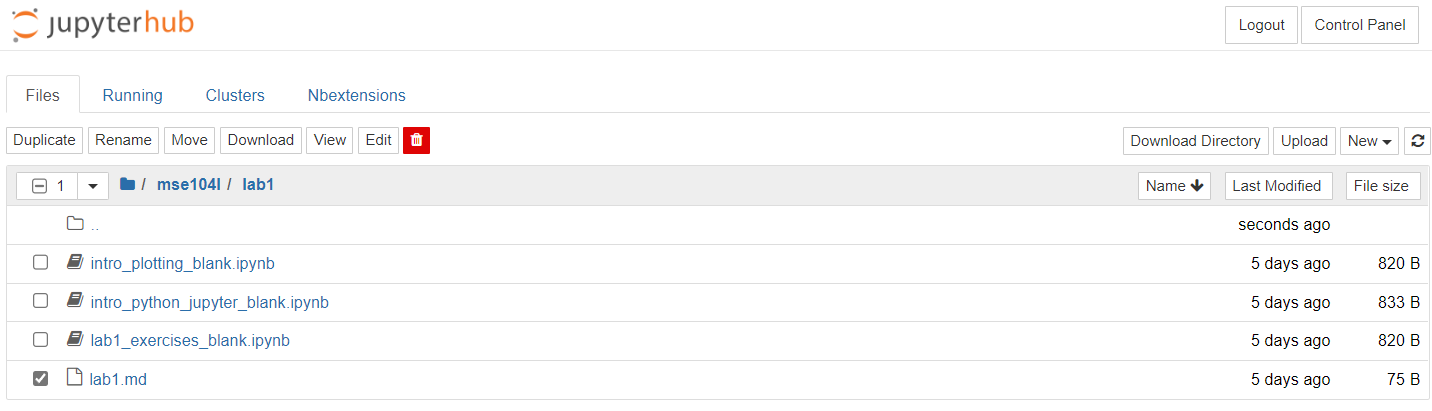
Here, you can:
Upload raw data files (e.g., CSVs from the diffractometer) by clicking Upload in the top-right corner and finding the files on your computer.
Download files (e.g., PNG figures) by selecting the check box and clicking Download in the menu options that appear.
Conclusion¶
This completes our introduction to the Jupyter Book interface. If you’re new to Python, we’ve included an accompanying notebook on the next page that goes through the fundamental commands you’ll likely need to complete all of the Python exercises for the labs. We hope it’s a helpful refresher.
If you’re already familiar with Python, you can proceed directly to Lab 1, which focuses on data visualization!